
Decoding Google's LearnLM technical paper
Lessons from fine-tuning an LLM for pedagogy

Read the updated version at bloom.study.
At their annual developer conference, I/O, Google introduced LearnLM, a family of Large Language Models (LLM) finetuned for learning. They have already begun to integrate it with their suite of products, including Google Search, Android and YouTube.
Aside from the exciting new product features, what most caught my eye was the 86-page technical paper that came with it. I haven’t seen too many breakdowns of the paper, so I thought I’d write one myself.
The paper, titled Towards Responsible Development of Generative AI for Education: An Evaluation-Driven Approach, describes their approach to fine-tuning Gemini 1.0 to be suitable for 1:1 conversational tutoring. Supervised fine-tuning (SFT) is a technique used to “align” an LLM, which involves curating a dataset of high-quality example conversations. Cameron R. Wolfe, Ph.D. writes a great explainer on supervised fine-tuning. Due to a lack of high quality tutoring data, they created their own, including transcripts from human tutoring of online research recruits, synthetically generated tutoring conversations between two LLMs, and “golden conversations”—transcripts written in partnership with teachers. They call this model LearnLM-Tutor, and they demonstrate that its education-related capabilities are better than a prompt-tuned Gemini 1.0 in seven different pedagogical benchmarks.
The greatest strength of this paper, however, does not lie in the results—it’s providing a framework for evaluating the use of Generative AI in education. The authors make the point that a shared framework for evaluation does not exist in learning science, EdTech and AI in education. Based on their participatory sessions and literature review, they prioritise a handful of pedagogical principles (quoted from the paper):
Encourage active learning: the learner should manipulate information through discussion, practice, and creation, instead of passively absorbing information
Manage cognitive load: the tutor should present information in multiple modalities, structure it well, and segment it into manageable chunks
Deepen metacognition: “thinking about thinking”, which enables learners to generalise their skills beyond a single context
Motivate and stimulate curiosity as this leads to self-efficacy and lifelong learning, and
Adapt to learners’ goals and needs by assessing the current state and the goals, and making a plan to bridge the gap
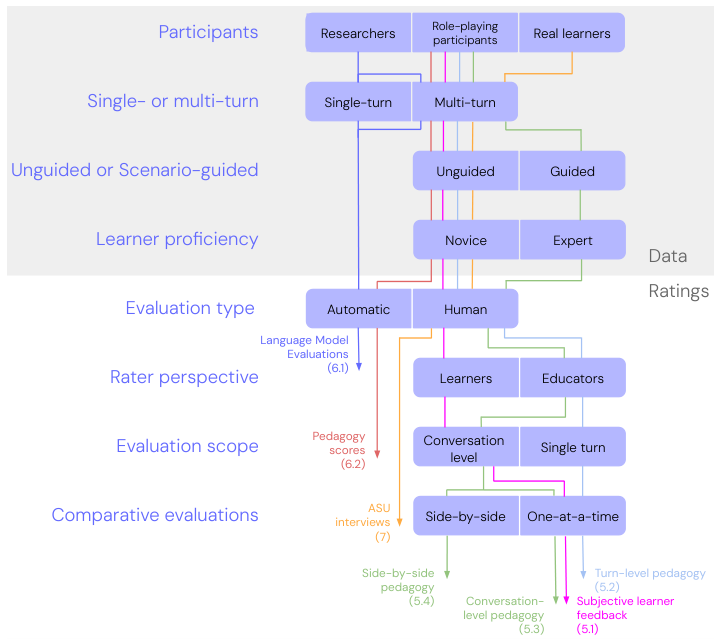
They also create an evaluation taxonomy which lays out the dimensions by which data collection and ratings can change. They create seven pedagogical benchmarks which they map to their taxonomy. I like that the authors say it’s their first attempt—they recognise that it may not be perfect and that they plan to “iterate, improve, and expand it in the future”. More work in education needs to be done this way.
Commentary on the results
Broadly speaking, LearnLM-Tutor is preferred over a prompt-tuned Gemini 1.0 over most dimensions. However, not all of the results are statistically significant, and there are certain categories where Gemini 1.0 is actually preferred.
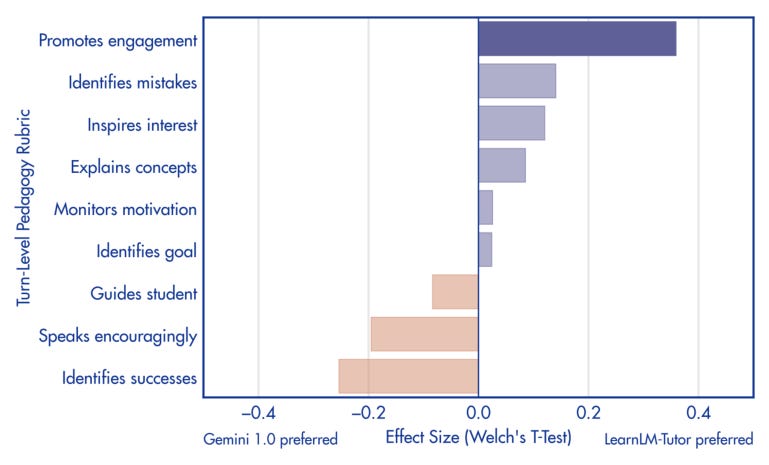
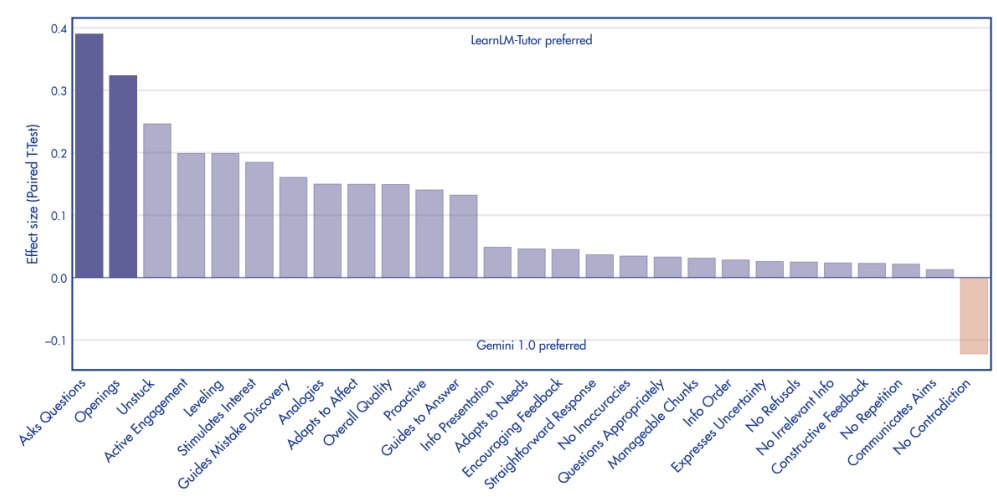
Based on teacher feedback (which encompassed 3 of the benchmarks) and automated evaluation, LearnLM-Tutor performs better than Gemini 1.0 on most dimensions. The dimensions where the improvement is statistically significant are promoting engagement, asking questions, and giving students openings to engage. Interestingly, it performs worse at identifying correct solutions, but better identifying mistakes and providing feedback. This may be a reflection of how hard it is to adjust the engrained behaviour of LLMs. It looks like the fine-tuning had the effect of making LearnLM-Tutor more critical overall, leading it to scrutinise even correct answers more rigorously than intended. It’s a classic case of “be careful what you wish for”.

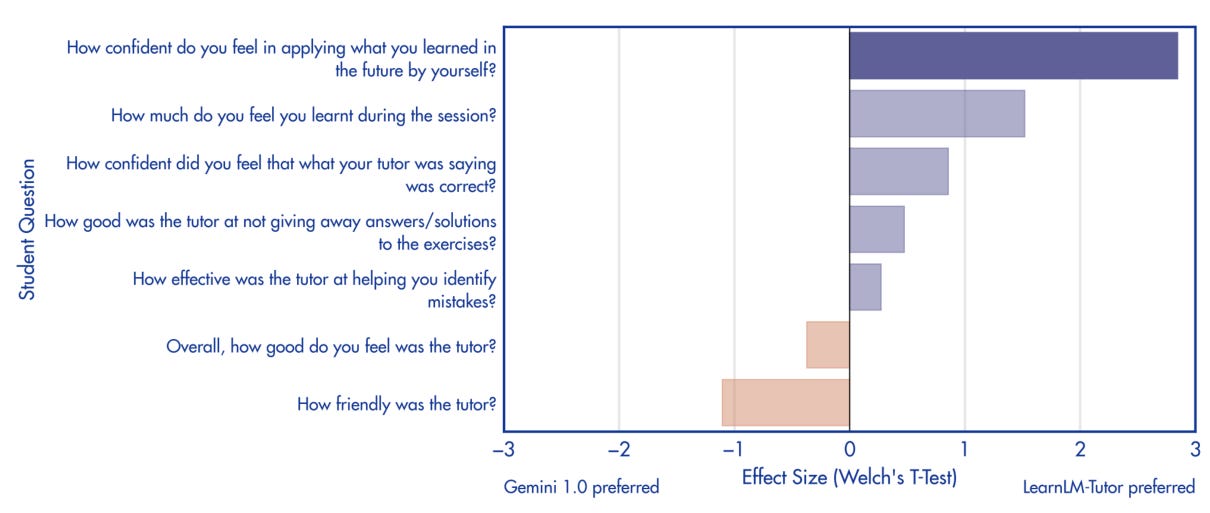
Broadly speaking, learners didn’t find LearnLM-Tutor as good as teachers did. Granted, the sample size was smaller and these were role-playing participants rather than real learners. Feedback from learners only showed one category where LearnLM-Tutor was statistically better than Gemini 1.0: learners felt more confident in applying what they learned in the future by themselves. Two categories LearnLM-Tutor actually performed worse than Gemini 1.0: “Overall, how good do you feel was the tutor?” (arguably the most important of the seven questions) and “How friendly was the tutor?”. A student’s perceived usefulness of a tool should not be under-estimated. For example, the Technology Acceptance Model (TAM) suggests that Perceived Usefulness (PU) is one of the key deciding factors of whether a user will use a technology.
Key takeaways
There is a lack of consensus on what is good pedagogy. The authors highlight that most learning science research is conducted in WEIRD countries (Western, Educated, Industrialized, Rich, and Democratic). Henrich, Heine and Norenzayan (2010) report that 96% of psychological samples come from countries with only 12% of the world’s population. But even within a WEIRD country, there is a wide divergence of what is considered good teaching. This is certainly true in my experience as an educator across high school and university levels in Australia (another WEIRD country). It will depend on many factors, including but not limited to the context, the subject, difficulty level, and prior learner knowledge.1 Even if we did have unified best practices on pedagogy, it’s unclear to what extent these principles would apply to educational technology, or indeed, an AI tutor.
Prompt engineering isn’t enough (at least now). There are core principles engrained into the model during pre-training and instruction tuning phases. In this case, prompt engineering is not enough to break an LLM free of them, even when using some of the state-of-the-arts prompts from Mollick & Mollick. While the authors demonstrate that fine-tuning achieves better results than prompt engineering, they note that it will be useful to explore other approaches, such as reinforcement learning from human feedback (RLHF). They highlight the main problems of a prompt engineering approach in Section D of their paper:
Multi-turn/proactivity: Gen AI models are optimised to be as helpful as possible in a “single turn” (i.e. in a single response). However, tutoring is inherently multi-turn.
Giving away answers: LLMs naturally give away the answer as quickly as possible, promoting cheating and creating over-reliance.
Sycophancy: LLMs tend to agree with the user and often struggle to identify mistakes. Learners can sway AI tutors away from being pedagogical because of the inherent tendency to please.
Uncertainty signaling: LLMs tend to present all information with the same level of certainty, hallucinated or not.
Pedagogy: LLMs are pre-trained on vast amounts of text scraped from the internet, most of which does not demonstrate high-quality of pedagogy.
Cognitive load / leveling: LLMs tend to produce long-form answers which are not ideal in the context of multi-turn tutoring.
The authors point out that the ability of gen AI models to follow prompts may vastly improve as the technology improves.
We need both human and automatic evaluation. Human evaluation is the gold standard for evaluation, but is time and effort intensive. Given that humans also have diverse preferences, sample sizes need to be larger in order to achieve meaningful insights. On the other hand, automated evaluation is much cheaper and quicker to perform. Promisingly, there was a strong correlation between the human pedagogy and the “LLM critic” pedagogy scores.

Take into account a broad range of stakeholders. The authors emphasise that “responsible development of educational AI systems requires engaging learners, educators, policymakers, and academic researchers”. It was encouraging to see that they engaged with over 100 people, ranging from role-playing learners, university students, and teachers.
AI tutors can be a safe space for learners. From their workshops with learners and teachers, one benefit of AI tutors over human tutors was that "learners felt more comfortable seeking clarification from AI tutors, perceiving AI tutors as less formal and less likely to induce fears of judgement”. This aligns with some of the early results we have seen in our implementations of the Bloom AI Tutor, where we have seen that groups of people who speak up less in class use Bloom more.
There are real risks to implementing educational AI systems. It was encouraging to see that the authors identified and attempted to mitigate many of the potential risks in implementing AI systems for education. These included “hallucinations, toxicity, biased outputs, and bias in the teaching level; changes in the learner’s behaviour, such as loss of autonomy, persuasion and emotional dependency; and privacy and surveillance, such as the collection of sensitive data and inferring and monitoring of emotions”. The authors also paid close attention to the risk of anthropomorphism, where students may perceive human-like characteristics in non-human systems. There are potential “downstream harms”, such as users experiencing “emotional attachments to AI systems”.
Points for improvement
Use state-of-the-art models. LearnLM-Tutor was fine-tuned from Gemini 1.0, which many would consider a “GPT-3.5-Turbo level” model. As of the time of writing, Artificial Analysis puts Gemini 1.0 Pro’s quality index at 62, versus GPT-4o at 100 and GPT-3.5-Turbo at 65. “GPT-4” level models are massively better, and by the time GPT-5 comes along, who knows, these results might end up being irrelevant! Of course, it’s very understandable—so much progress happens in AI from the time you start a study, to when you publish the results. It highlights the importance of a quick, iterative approach which is repeatable across different models. The authors’ automated evaluation approach strikes me as something they could easily re-run on their latest version of Gemini.
More results from real-world implementations. The majority of results in the paper were with teacher evaluations and role-playing participants. I would have liked to see more detailed data and results from the real-world implementations of LearnLM-Tutor. It was interesting to see that out of the 110 students who opted in to use HallMate, 65% of them interacted with HallMate. As with most educational tools, usage was variable. While there were some insights from interviewing 10 of the students who used it as part of ASU’s Study Hall, they were limited.
Benchmark with human tutoring. Because the metrics are almost all in comparison to a prompt-tuned Gemini 1.0, we only get a relative sense of how good LearnLM-Tutor is. The results are not surprising. In the words of Dan Meyer (see his take here):
This is like asking, “Who can run the 100 meter dash faster—a Roomba or a customized Roomba?” all while Usain Bolt is standing there in lane three.
There are ways to directly compare human tutors and AI tutors. And while there won’t be a single metric which captures all of the nuance of being a good tutor, we can certainly piece together a picture of where they are effective and where they fall short.
Break down the results by demographics and subject. As the authors noted themselves, optimal pedagogy differs by context. I suspect some of the human evaluation results would differ by subject, or age of student. The subjects noticeably skew towards STEM, with 30 out of the 53 learners included in the results choosing a math, CS, chemistry or biology video to learn from before interacting with the AI tutor.
Thanks for reading! If you have any feedback, or want to suggest some topics I should write about, reach out to me on Twitter or LinkedIn.
I like that the authors visualise pedagogical behaviour as a “complex manifold lying within a high-dimensional space of all possible learning contexts (e.g. subject type, learner preferences) and pedagogical strategies and interventions (some of which may only be available in certain contexts)”.

LearnLM-Tutor is an AI educational assistant meticulously crafted by Google DeepMind, focusing on one-on-one teaching and tutoring. This model not only helps students solve specific problems through providing instant feedback, supporting multi-turn dialogues, identifying mistakes, and giving positive feedback, but also commits to enhancing their self-learning abilities and critical thinking skills. In addition, it features customized learning plans, multi-disciplinary teaching support, and tracking of learning progress, providing solid support for the comprehensive growth of students.